In today’s data-driven world, safeguarding sensitive information is paramount. Personally Identifiable Information (PII) refers to any data that can be used to identify an individual, such as names, Social Security numbers, email addresses, and more. As organizations increasingly rely on cloud-based platforms for analytics, ensuring this data remains secure has become more challenging than ever. Mishandling PII not only breaches regulatory compliance but also risks reputational damage.

This article delves into how DataBricks, a leading cloud-based data platform, helps address these concerns. It covers (1) What is PII and why it matters (2) The importance of data masking (3) Implementing PII masking in DataBricks
Keywords: DataBricks, PII, Data Masking, Data Security, Cloud Analytics
What is PII and Why It Matters?
PII (Personally Identifiable Information) refers to any data that can be used to identify an individual directly or indirectly. This type of data plays a crucial role in personal identification, online transactions, and organizational processes. However, because of its sensitive nature, mishandling PII can lead to severe consequences such as identity theft, financial fraud, and regulatory penalties. PII encompasses two categories:
- Direct Identifiers: Information that can uniquely identify a person, such as names, Social Security numbers, passport details, and biometric data (e.g., fingerprints or facial recognition).
- Indirect Identifiers: Data that, when combined with other information, can identify a person, such as IP addresses, date of birth, or workplace details.
PII is critical for business operations, customer relationships, and compliance with global privacy laws. Mismanagement or exposure of PII can result in legal penalties under regulations like the General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), or the Health Insurance Portability and Accountability Act (HIPAA). Beyond regulatory fines, data breaches involving PII damage customer trust, leading to reputational harm. Examples of PII in the Real World:
- Healthcare Organizations: Hospitals and clinics manage patient records, including medical histories, insurance information, and social security numbers. A breach here can compromise not just privacy but health security.
- Educational Institutions: Schools and universities collect data like student identification numbers, birthdates, and parental contact details. Misuse of this information can lead to phishing scams or unauthorized access to academic records.
The importance of data masking
Data masking is essential for protecting sensitive information like Personally Identifiable Information (PII) by altering it to conceal its true values while maintaining usability. It’s a vital tool for organizations to safeguard data, ensure compliance with privacy regulations like GDPR and HIPAA, and minimize security risks. It helps in:
- Data Security: Prevents unauthorized access to meaningful data, even during breaches.
- Regulatory Compliance: Helps meet legal requirements for data privacy.
- Safe Data Sharing: Enables secure collaboration with third parties.
- Testing and Development: Allows the use of realistic data in non-production environments without exposing sensitive details.
There are two techniques used to protect Personally Identifiable Information (PII) in datasets, documents, or communications to ensure privacy and compliance with regulations like GDPR or HIPAA.
- Redacting: Redaction involves removing or completely obscuring sensitive information from a document or dataset. In the context of PII, redacting means replacing PII data with a placeholder (like
REDACTED), so it is no longer visible to unauthorized users but retains its place in the data structure or document. - Masking: Masking is the process of obfuscating PII by replacing part of the data with a specific mask (often
******or other characters), leaving only part of the data visible. The original sensitive data is still there but is not fully exposed. This allows for partial visibility or use of the data without fully compromising privacy and helps in running analytical operation which might not be possible with redacted data.
PII redacting and masking in DataBricks
Redacting or masking can be done using some helper function provided by DataBricks and using dynamic views. For this demo we will be focusing on address, SSN (Social Security Number) inside the employee table which are PII data.
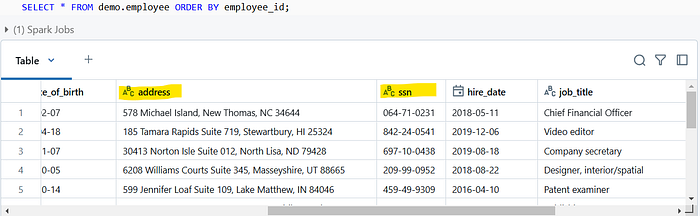
Consider a scenario where dev team want to access this data for some work. We cannot share the table directly due to privacy and security concerns. However, we still want to allow dev team to access certain data for work purposes without exposing sensitive PII information. In this case, we can apply data masking or data redaction to provide them with sanitized or obfuscated versions of the data.
For this demo, I have created a dev group in the Databricks workspace to simulate a real-world scenario where different user groups require different levels of access to sensitive information. To manage this, we will use DataBricks is_member function to check which group the user belongs to and apply data redaction or masking accordingly.
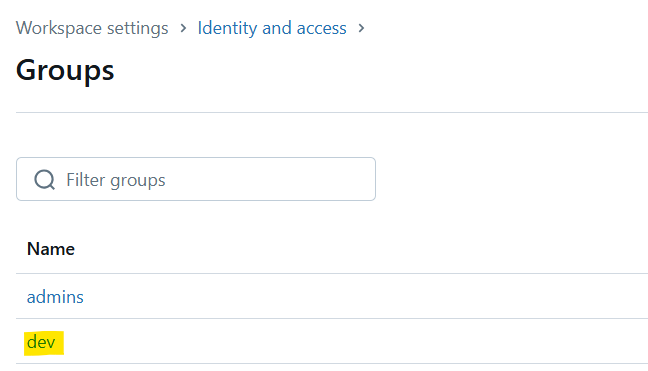
Before we create the dynamic view we will need a custom function function for masking:
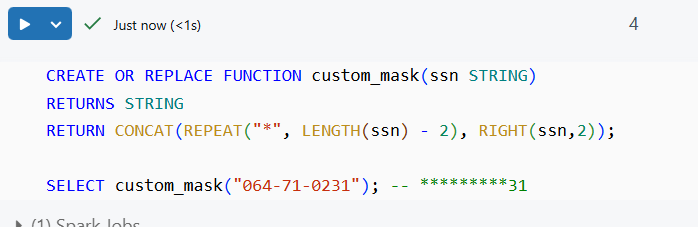
The above function will mask all the characters of the data apart from the last 2 characters as given in the commented example. Now we will utilize DataBricks dynamic views to create a view where we will redact the address column and mask the SSN. The name of the view is dev_employee and we will use the is_member and custom_mask functions:
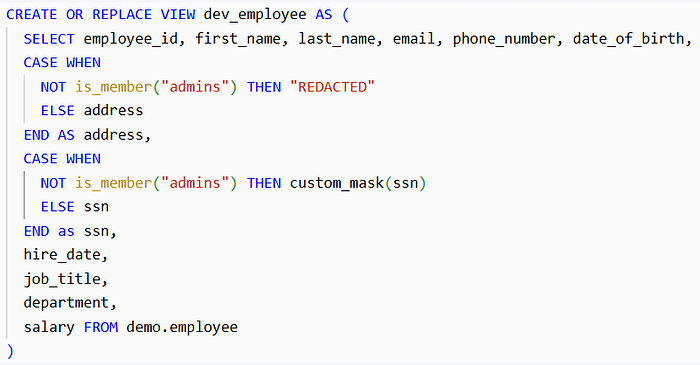
Now this view can be shared with dev group by granting permissions on the view and custom_maskfunction, and they should be able to continue with their work. Now let’s see how this view will return the data for admins and dev groups.
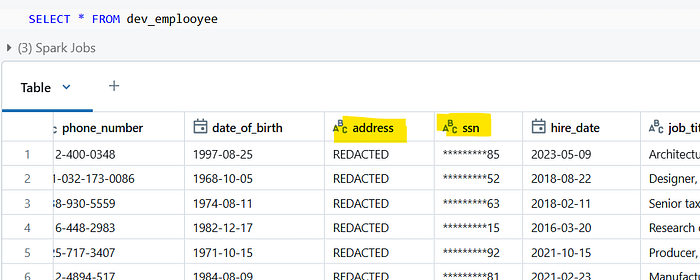
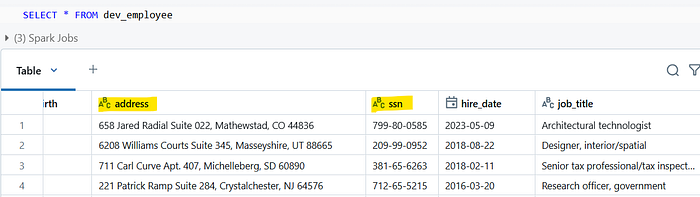
In this demo, we demonstrated how to effectively manage access to sensitive data in Databricks by leveraging the is_member function. By creating different access levels for user groups, such as admin and dev, we can ensure that sensitive data like employee addresses and SSNs is only visible to authorized personnel. DataBricks also provides more functions like current_user() which can also be used for the same purpose.
This approach allows organizations to maintain strict privacy and security controls over sensitive data while still enabling teams to perform necessary tasks without exposing sensitive details. By using role-based access controls and data obfuscation techniques, you can ensure compliance with data protection regulations and safeguard sensitive information.
If you are here, thank you for your time reading this article. If you like this article give me a clap and feel free to connect with me on Twitter, GitHub and LinkedIn. Checkout my old articles here: https://aps08.medium.com
